...
...
Теперь будем сокращать
Что делает механизм автокорреляции (описать, что это такое и зачем он нужен)
In SimpleOne, you can integrate
Со стороны системы мониторинга - алерты, с с нашей стороны в ответ - ивенты. Мы их типизтируем, чтобы механизм корреляции уже дальше поступал как надо.
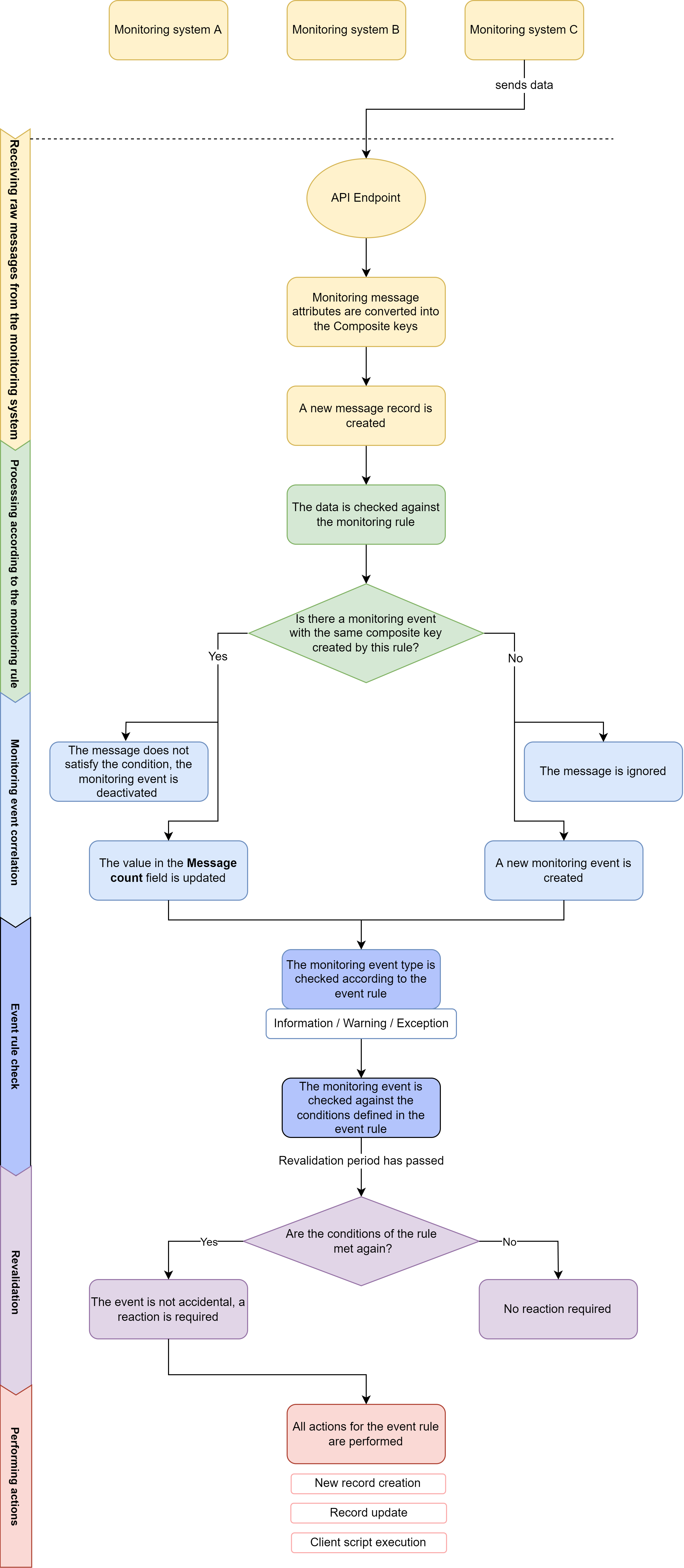
У нас настроен обмен данными между внешней системой мониторинга и системой симпл. Регулярный, по апи, например, раз в 5 сек.
У нас есть три типа ивентов: exception, warning, information. Отсортированы по убыванию важности.
Event correlation engine
...
...
.
The following scheme shows the whole process of the monitoring and event management:
Exception Events
Exception events
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
В данном случае даже не используется механизм Антилребезга.
- В какой-то момент, в очередной такт синхронизации система мониторинга сообщает "сервер такой-то недоступен (красное событие)".
- на стороне симпл, в соответствии с заданными настройками, создался ивент с типом exception, идентичный алерту, сервер такой-то недоступен. он имеет статус active.
- Ждём заданный период антидребезга (например, три минуты)
- Смотрим статус ивента, соответствующего этому алерту (система мониторинга регулярно обновляет статусы алертов, а статусы ивентов синхронизируются с ними).
- Если статус ивента по прежнему active - незамедлительно создаем инцидент
- Если статус ивента сменился на inactive - инцидент не создаётся.
Warning - это менее приоритетные ивенты. Например, если заканчивается свободное дисковое пространство. Тут логика работает немного иначе.
- В какой-то момент, в очередной такт синхронизации система мониторинга сообщает "на сервере таком-то осталось столько-то свободного дискового пространства" (оранжевое событие);
- Мы создаем ивент категории warning, но антидребезг пока не запускаем. По нашим настройкам, нам необходимо дождаться второго такого же активного ивента.
- Поступил второй event типа warning. Если сейчас у нас два активных eventa типа warning по одному alert, то
- Запускаем механизм антидребезга, ждём заданный период антидребезга (например, три минуты).
- Смотрим на статусы eventов, соответствующих этому alert (система мониторинга регулярно обновляет статусы алертов, а статусы ивентов синхронизируются с ними).
- Если оба ивента имеют статус active - незамедлительно создаем инцидент
- Если хотя бы один ивент перешёл в inactive - инцидент не создаётся.
суть механизма автокорреляции
exception
внешняя система мониторинга - от нее прилетает alert, например, что сервер недоступен. сейчас реализованы три типа ивентов: exception, warning, information.
регулярно, например, раз в 5 секунд, у нас происходит обмен данными по апи с системой мониторинга и системой симпл.
- в какой-то момент (такт синхронихзации) от внешней системы мониторинга приходит alert "сервер такой-то недоступен (красное событие)".
- на стороне симпл, в соответствии с заданными настройками, создался ивент с типом exception, идентичный алерту, сервер такой-то недоступен. он имеет статус active.
- У нас задано: если возник один exception event - значит, надо создать инцидент. Мы готовимся это сделать. Сработал механизм автокорреляции. Его суть в том, что когда мы создаем инцидент из ивента, т.е. из ивента категории иксепшен мы создаем инцидент безусловно, из ивента категории варнинг нам нужно накопить такой же ивент, чтобы было не менее 2. Ивентов категории информейшен должно быть аномальное количество за промежуток времени, например, (такие ивенты самые незначительные, это, например, пользователь залогинился или разлогинился), это нормально иметь такие ивенты и ненормально, если у нас за 1 минуту поступит 50 таких ивентов, нужно в таком случае создавать инцидент.
- Вот когда у нас за период времени аномальный всплеск количества таких ивентов свыше заданного, у нас создаётся инцидент.
Вот зависимость от типа ивента и дальнейшие действия по регистрации инцидента это и называется механизм корреляции ивентов. Механизм дебаунс накладывается поверх него.
- Пришел ивент категории иксепшен.
- Мы готовы создать инцидент, но по истечении периода антидребезга.
- Ждем три минуты, заданный период антидребезга.
- Прошел этот период, мы смотрим на состояние ивента, а он уже "позеленел", т.е. состояние inactive. Потому что система мониторинга пролила новый статус на него за очередной такт синхронизации. И алерт позеленел, и ивент позеленел, они синхронизируются, соответственно, мы не создаем инцидент. Антидребезг помог нам избежать создания инцидента, который сразу же будет неактуален.
Ситуация другая
- Пришел ивент категории иксепшен.
- Мы так же готовы создать инцидент., но надо подождать на антидребезг.
- Антидребезг прошел, мы вернулись, система мониторинга подтверждает активный статус ивента, он действительно актуален, т.е. активен этот ивент, и мы незамедлительно создали инцидент.
В случае варнингов. Тут логика сложнее.
Если тут сервер был недоступен, то у нас здесь просто, например, превышение порогового значения жесткого диска, осталось 50 мб. Мы создаем ивент на основе этого события. Поскольку у нас тип ворнинг, мы не кидаемся сразу запускать антидребезг и создавать инцидент. У нас по правилам, если ивент варнинг, то надо подождпть такого же второго активного ивента, что и происходит. Через заданный промежуток времени синхронизация происходит, доставляется ивент, уже с другим порогом, осталось 40 мегабайт. Правило удовлетворилось, мы приступаем к антидребезгу. Мы ожидаем антидребезг 3 минуты, как настроено, возвращаемся и видим, что немного место освободилось и стало место 45 свободно. Т.е. остался один ивент. Мы инцидент не создаем. Возвращаемся в исходное состояние. Опять приходит ивент о том, что 50 мегабайт осталось, ждём следующий, ничего не делаем, приходит ещё один, что осталось 40, мы опять запускаем антидребезг, ждём, тут ещё насыпалось, что осталось 30 и 20 мегабайт. Мы незамедлительно создаем инцидент о том, что заканчивается место на диске.
А в случае информейшен задается период времени. Нам нужно, чтобы поступили однотипные события, одинаковые за период времени , т.е. надо, чтобы было, скажем, больше 10 за 1 минуту таких. Этим и отличается тип информейшен от остальныхт типов.
...